

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
“图书在版编目数据”检索数据部分中的“IV•分类号”是根据出版物的()按《中国图书馆分类法》的基本大类标引的类目。
A.主题
B.内容的学科属性
C.名称
D.出版日期
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
A.主题
B.内容的学科属性
C.名称
D.出版日期
答案
 更多““图书在版编目数据”检索数据部分中的“IV•分类号”是根据出版物的()按《中国图书馆分类法》的基本大类标引的类目。”相关的问题
更多““图书在版编目数据”检索数据部分中的“IV•分类号”是根据出版物的()按《中国图书馆分类法》的基本大类标引的类目。”相关的问题
第1题
第2题
利用ATTEND.RAW中的数据。
(i)在例6.3的模型中,推出
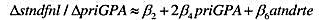
当priGPA=2.59和atndrte=82时,利用方程(6.19)来估计偏效应。对你的估计进行解释。
(ii)证明可将方程写成
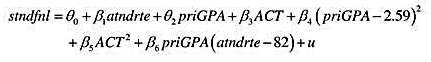
其中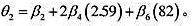 (注意,截距已发生变化,但并不重要。)用它求出第(i)部分得到的θ2的标准差。
(注意,截距已发生变化,但并不重要。)用它求出第(i)部分得到的θ2的标准差。
第3题
利用CONSUMP.RAW中的数据。
(i)估计一个反映真实人均(非耐用品和服务)消费增长与真实人均可支配收入增长之间关系的简单回归模型,并都使用对数变化量表示。用通常形式报告结果。解释方程并讨论统计显著性。
(ii)在第(i)部分的方程中添加真实人均可支配收入增长的一期滞后。你对消费增长的滞后调整有何看法?
(iii)在第(i)部分的方程中添加真实利率,它影响消费增长吗?
第4题
A.数据汇总节点;
B.服务器客户端AGENT;
C.统一管理平台;
D.仪表监控平台
第5题
本题使用INJURY.RAW中的数据。
(i) 使用肯塔基州的数据, 增加male, married以及全套行业和工伤类型虚拟变量作为解释变量, 重新估计方程(13.12)。在控制了这些其他因素后, afchnge-high earn的估计值有何变化?这个估计值仍然统计显著吗?
(ii)你对第(i)部分中较小的R°有什么看法?这是否意味着这个方程无用呢?
(iii)用密歇根州的数据估计方程(13.12)。比较密歇根州和肯塔基州的交互项估计值。密歇根州的估计值在统计上显著吗?你对此如何解释?
第6题
本题使用CRIME4.RAW。
(i)在数据集中增加每个工资变量的对数,然后用一阶差分估计模型。问这些变量的引入如何影响例13.9中那些司法变量的系数?
(ii)第(i)部分中的工资变量都有预期的符号吗?它们是联合显著的吗?试解释。
第7题
本题使用LOANAPP.RAW中的数据。
(i)有多少个观测的obrat>40,即其他债务负担超过其总收入的40%?
(ii)在计算机习题C7.8中,去掉o brat 40的观测,重新估计第(iii)部分中的模型。white的系数估计值和t统计量将会怎样?
(iii) 看起来对所使用的样本过度敏感吗?
看起来对所使用的样本过度敏感吗?
第9题
利用BARIUM.RAW中的数据。
(i)在方程(10.22)中增加一个线性时间趋势。除了趋势变量以外的其他变量是统计上显著的吗?
(ii)在第(i)部分估计的方程中,检验除了时间趋势以外所有其他变量的联合显著性。你能得到什么结论?
(iii)在这个方程中添加月度虚拟变量,以检验季节性。增加月度虚拟变量对其他估计值及其标准误有重要影响吗?
第10题
本题要用到HTV.RAW中的数据。
(i)考虑一个加入了父母受教育程度变量的工资方程
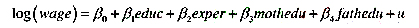
表述原假设:父亲与母亲的受教育程度对log(wage)具有相同影响。
(ii)估计第(i)部分中的模型,同时谈谈你对β,和队大小的看法。
(iii)在5%的显著性水平上,相对于双侧备择假设,通过构造一个95%的置信区间来检验第(i)部分中的原假设。你得到的结论是什么?
第11题
用到MROZ.RAW中的数据。
(i)用log(hours)作为因变量重新估计教材例16.5中的劳动供给函数。将估计出的弹性(现在是常数)与教材方程(16.24)在平均工作小时数处所得到的估计值相比较。
(ii)在第(i)部分的劳动供给方程中,容许educ因遗漏了能力变量而成为内生变量。用motheduc和fatheduc作为educ的Ⅳ。记住,你现在在方程中有两个内生变量。
(iii)检验第(ii)部分2SLS估计中过度识别约束。这些Ⅳ通过检验了吗?



















