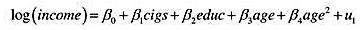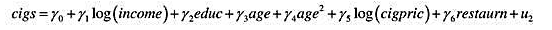题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题要用到HTV.RAW中的数据。 (i)考虑一个加入了父母受教育程度变量的工资方程 表述原假设:父
本题要用到HTV.RAW中的数据。
(i)考虑一个加入了父母受教育程度变量的工资方程
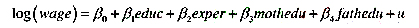
表述原假设:父亲与母亲的受教育程度对log(wage)具有相同影响。
(ii)估计第(i)部分中的模型,同时谈谈你对β,和队大小的看法。
(iii)在5%的显著性水平上,相对于双侧备择假设,通过构造一个95%的置信区间来检验第(i)部分中的原假设。你得到的结论是什么?
 答案
答案
查看答案

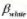 看起来对所使用的样本过度敏感吗?
看起来对所使用的样本过度敏感吗?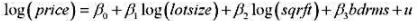
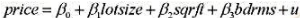
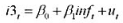 。
。
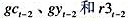 ,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?
,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?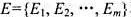 和进行这些实验需要使用的全部仪器的集合
和进行这些实验需要使用的全部仪器的集合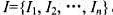 .实验Ej需要用到的仪器是I的子集
.实验Ej需要用到的仪器是I的子集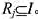 .配置仪器Ik的费用为ck美元.实验Ej的赞助商已同意为该实验结果支付pj美元.W教授的任务是找出一个有效算法,确定在一次太空飞行中要进行哪些实验并因此而配置哪些仪器,才能使太空飞行的净收益最大.这里的净收益是指进行实验所获得的全部收入与配置仪器的全部费用的差额.
.配置仪器Ik的费用为ck美元.实验Ej的赞助商已同意为该实验结果支付pj美元.W教授的任务是找出一个有效算法,确定在一次太空飞行中要进行哪些实验并因此而配置哪些仪器,才能使太空飞行的净收益最大.这里的净收益是指进行实验所获得的全部收入与配置仪器的全部费用的差额.