

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[判断题]
位变量图标显示功能是把一个数据变量的每个位(bit)的0/1状态对应8种不同显示方案中的两种,用IC
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
答案
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
答案
 更多“位变量图标显示功能是把一个数据变量的每个位(bit)的0/1状态对应8种不同显示方案中的两种,用IC”相关的问题
更多“位变量图标显示功能是把一个数据变量的每个位(bit)的0/1状态对应8种不同显示方案中的两种,用IC”相关的问题
第1题
考虑一个雇员水平的模型
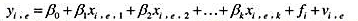
其中无法观测变量f是在一个给定的企业i内,对每个雇员的“企业效应”。误差项vi,e是企业i中雇员e所独具的。诸如方程(8.28)中的综合误差就是ui,e=fi+ui,e.

(iv)讨论第(ii)部分对于利用企业层次的平均数据进行WLS估计的意义,其中第i次观测所用的权数就是通常的企业规模。
第2题
(i)考虑静态非观测效应模型

其中,enrolit表示学区总注册学生人数,lunchit表示学区中学生有资格享受学校午餐计划的百分数。(因此lunchit是学区贫穷率的一个相当好的度量指标。)证明:若平均每个学生的真实支出提高10%,则math4it约改变β1/10个百分点。
(ii)利用一阶差分估计第(i)部分中的模型。最简单的方法就是在一阶差分方程中包含一个截距项和1994~1998年度虚拟变量。解释支出变量的系数。
(iii)现在,在模型中添加支出变量的一阶滞后,并用一阶差分重新估计。注意你又失去了一年的数据,所以你只能用始于1994年的变化。讨论即期和滞后支出变量的系数和显著性。
(iv)求第(iii)部分中一阶差分回归的异方差-稳健标准误。支出变量的这些标准误与第(iii)部分相比如何?
(v)现在,求对异方差性和序列相关都保持稳健的标准误。这对滞后支出变量的显著性有何影响?
(vi)通过进行一个AR(1)序列相关检验,验证差分误差rit=Δuit含有负序列相关。
(vii)基于充分稳健的联合检验,模型中有必要包含学生注册人数和午餐项目变量吗?
第4题

第5题
A.官方知识库每个问题最多设置100个答案
B.官方知识库的问题答案支持变量功能
C.官方知识库不能按商品ID搜索问题
D.官方知识库的问题若用不到,支持将该问题删除
第6题
A.直方图可以很清楚地看出每个变量占总体的比重
B.盒型图越扁说明数据越分散
C.散点图主要用于对比不同变量的大小
D.饼状图可以很清楚地看到每个变量占总体的比重
E.K线图呈现“十”字,说明当天开盘价等于收盘价
第7题
(i)你为什么会把这些数据归类为聚类样本?大致上,你预期能从一个典型学生得到大概多少次观测?
(ii)写出一个类似于教材方程(14.12)那样的模型,用到课率和其他特征去解释期终考试成绩。以s作为学生下标和c作为课程下标,对同一个学生哪个变量是不变的?
(iii)如果你把所有的数据混合起来并使用OLS,那么,对影响成绩和到课率的非观测学生特征,你正在做什么假定呢?SAT和学期前GPA在这方面扮演着什么角色呢?
(iv)如果你认为SAT和学期前GPA不足以刻画学生能力,你如何估计到课率对期终考试成绩的影响呢?
参考答案:


6.利用计量经济软件 中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
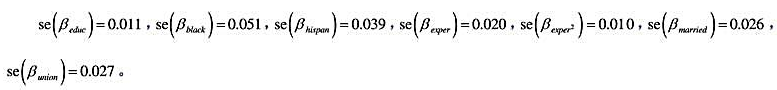
(i)这些标准误与非稳健标准误相比一般如何?为什么?
(ii)混合OLS的稳健标准误与RE的标准误相比如何?解释变量是否随时间变化有什么关系吗?
第9题
利用KIELMC.RAM中的数据。
(i)变量dist是从每个房屋到焚烧炉位置的英尺距离。考虑模型

如果建造焚烧炉会减少其附近的房屋价值,那么δ1的符号将是什么?若β1>0,则意味着什么?
(ii)估计第(i)部分中的模型并按通常的方式报告结果。解释y81-log(dist)的系数。你得到了什么结论?
(iii)在方程中增加age,age2,rooms,baths,log(intst),log(land)和log(area)。现在,你对焚烧炉对房屋价值的影响会作出什么结论?
第10题
A.③②⑤①④
B.③⑤②④①
C.③①④⑤②
D.③④①②⑤
第11题
A.对于无法读取参数的商品单独设置答案
B.删掉原使用变量的答案,使用通用答案
C.增加一个新的通用答案
D.在答案中把店铺所有商品都关联上



















