

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
下列哪个现象会使得通常的OLS中t统计量无效()。
A.异方差
B.X有异常值
C.误差项没有正态分布,但是数据满足中心极限定理要求
D.回归方程没有常数项
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
A.异方差
B.X有异常值
C.误差项没有正态分布,但是数据满足中心极限定理要求
D.回归方程没有常数项
答案
 更多“下列哪个现象会使得通常的OLS中t统计量无效()。”相关的问题
更多“下列哪个现象会使得通常的OLS中t统计量无效()。”相关的问题
第1题
A.当异方差出现时,最小二乘估计是有偏的和不具有最小方差特性
B.当异方差出现时,常用的t和
C.异方差情况下,通常的OLS估计一定高估了估计量的标准差
D.如果OLS回归的残差表现出系统性,那么说明数据中不存在异方差性
E.如果回归模型中遗漏一个重要变量,那么OLS残差必定表现出明显的趋势
F.检验失效
第2题
(i)你为什么会把这些数据归类为聚类样本?大致上,你预期能从一个典型学生得到大概多少次观测?
(ii)写出一个类似于教材方程(14.12)那样的模型,用到课率和其他特征去解释期终考试成绩。以s作为学生下标和c作为课程下标,对同一个学生哪个变量是不变的?
(iii)如果你把所有的数据混合起来并使用OLS,那么,对影响成绩和到课率的非观测学生特征,你正在做什么假定呢?SAT和学期前GPA在这方面扮演着什么角色呢?
(iv)如果你认为SAT和学期前GPA不足以刻画学生能力,你如何估计到课率对期终考试成绩的影响呢?
参考答案:


6.利用计量经济软件 中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
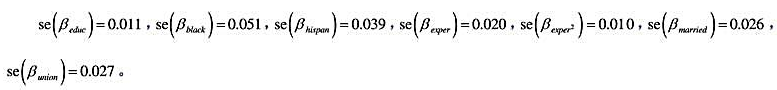
(i)这些标准误与非稳健标准误相比一般如何?为什么?
(ii)混合OLS的稳健标准误与RE的标准误相比如何?解释变量是否随时间变化有什么关系吗?
第3题
A.标题一般放在图的正下方
B.纵、横轴的刻度值应按从小到大的顺序排列
C.纵横轴的比例一般为1:1
D.通常需附图例说明不同事物的统计量
E.绘制图形应注意准确、美观和清晰
第4题
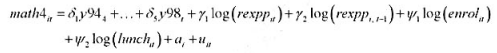
其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型, 并报告通常的标准误。为使得ai的期望值可以非零, 你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差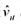 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用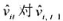 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?

第7题
A.T落在界值范围内,P则小于相应概率
B.T落在界值范围内,P则大于相应概率
C.T落在界值范围外,P则大于相应概率
D.T落在界值范围上,P则大于相应概率
E.以上都不对
第9题
A.在方差分析中,如果两个因素的水平数一样多,则哪个因素的F统计量的值越大,则哪个因素越有可能是一个显著的影响因素
B.在方差分析中,如果两个因素的水平数一样多,则哪个因素的F统计量对应的Sig值越大,则哪个因素越有可能是一个显著的影响因素
C.在进行方差齐性检验时,如果LeveneF统计量的值越大,则越有可能得出方差齐性的结论
D.在进行方差齐性检验时,如果LeveneF统计量对于的Sig值越大,则越有可能得出方差齐性的结论
E.如果不满足方差齐性要求,则方差分析的结论就不可靠标记
第10题
A.t分布
B.F分布
C.M分布
D.卡方(χ2)分布
第11题
利用AIRFARE.RAW中的数据。我们的兴趣在于估计模型
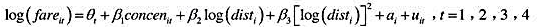
其中,θt意味着,我们容许每年的截距有所不同。
(i)用混合OLS估计上述方程,注意包含年度虚拟变量。若Δconcen=0.10,估计fare提高了多少个百分点?
(ii)的通常OLS的95%置信区间是什么?它为什么可能不太可靠?如果你有能计算充分稳健标准误的统计软件,求出β1的充分稳健的95%置信区间。与通常的置信区间相比较,并评论。
(iii)描述log(dist)的二次项出现的情况。特别是,dist取何值时,log(fare)和dit之间开始出现正向关系。[提示:首先计算log(dist)的转折点,然后取指数。]转折点出现在数据范围之外吗?
(iv)现在用随机效应法估计方程。β1的估计值有何变化?
(v)现在用固定效应法估计方程。β1的FE估计值是多少?它为何与RE估计值相当类似?(提示:RE估计的入是多少?)
(vi)指出由ai刻画的两个航线特征(除起降距离之外)。这些特征可能与concenit相关吗?
(vii)你相信航线更集中会提高飞机票价吗?最佳估计值是什么?



















