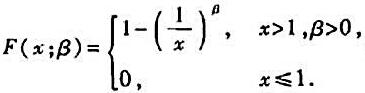题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[判断题]
极大似然估计是把待估计的参数看作不确定的未知量,根据训练样本集的数据求取该未知参数的最优估计值。()
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
答案
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
答案
 更多“极大似然估计是把待估计的参数看作不确定的未知量,根据训练样本集的数据求取该未知参数的最优估计值。()”相关的问题
更多“极大似然估计是把待估计的参数看作不确定的未知量,根据训练样本集的数据求取该未知参数的最优估计值。()”相关的问题
第2题
A.最大似然估计是使似然函数最大的那个参数作为估计
B.条件中位数估计为先验概率密度的中位数作为估计
C.最小均方估计等于被估计量的条件均值
D.观测数据的获得可以减少待估计参数的不确定性
第3题
在例9.1中,我们narr86在的一个线性模型中增加二次项pcrv2、ptime86²和inc 862。
(i)利用CRIME L RAW中的数据, 在例17.3的泊松回归中同样增加这些项。
(ii)根据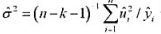 估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?
估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?
(iii)利用第(i)部分和第(ii)部分的结论及教材表17.3,计算这三个平方项联合显著性的准似然比统计量。你得到什么结论?
第4题
设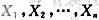 为来自正态总体N(μ,σ2)时的简单随机样本,其中μ0已知,σ2>0未知.
为来自正态总体N(μ,σ2)时的简单随机样本,其中μ0已知,σ2>0未知.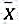 和S2分别表示样本均值和样本方差.
和S2分别表示样本均值和样本方差.
(I)求参数σ2的最大似然估计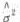
(II)计算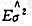 和
和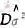
第6题
A.参考专家经验、既往研究、对本研究的期望(OR,RR)、实际的公共卫生学或临床意义等;
B.开展预实验来估计参数
C.也可以随意进行设置
D.在经费、各类资源和可行性允许的范围内选择最保守(即最大)的估计值
E.对不确定的参数,利用合理范围内的一组值计算出多个样本量方案,然后再由研究者根据实际情况做出选择
第8题
利用PHILLIPS.RAW中的数据。
(i)用直至1997年的数据估计教材(18.48)和(18.49)中的模型。参数估计值与教材(18.48)和教材(18.49)中的结果相比有很大不同吗?
(ii)用新方程预测unem1998,小数点后保留两位数。哪个方程预测得更好?
(ii)我们在正文中讨论过,用教材(18.49)预测unem1998为4.90.把它与利用直至1997年的数据得到的预测相比较。多用一年数据求得的参数估计值能给出更好的预测吗?
(iv)用教材(18.48)中估计的模型求出unem的提前两期预测值。即利用α=1.572,p=0.732,h=2时的教材方程(18.55)预测unem与把unem1997=4.9代入教材(18.48)所得到的提前一期预测值相比,哪一个更好?
第10题
设x1,x2,...,xn是取自连续型总体X的样本观察值,X的概率密度为
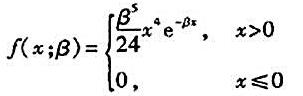
其中参数β>0未知,求β的最大似然估计值。
第11题
本题使用CRIME4.RAW。
(i)在数据集中增加每个工资变量的对数,然后用一阶差分估计模型。问这些变量的引入如何影响例13.9中那些司法变量的系数?
(ii)第(i)部分中的工资变量都有预期的符号吗?它们是联合显著的吗?试解释。
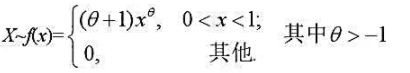 X1,X2…,Xn而是X的一个样本,求
X1,X2…,Xn而是X的一个样本,求 的矩估计量及极大似然估计量。
的矩估计量及极大似然估计量。